
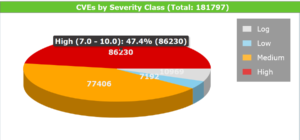
Ilość zgłoszonych podatności do bazy CVE w czasie pisania artykułu wynosiła w przybliżeniu 200 000. Oczywiście dotyczy to różnego typu sprzętu i oprogramowania. Z roku na rok jest ich więcej, niestety również będących tzw. podatnościami typu zero-day. Szybkość działania jest w tym przypadku kluczowa – reakcja od momentu pozyskania informacji o podatności do podjęcia działań mających na celu jej usunięcie. Jeżeli nie jest możliwe usuniecie podatności, wykonanie tymczasowego obejścia problemu. Trudność w skutecznym zaradzeniu wykrytymi podatnościami jest tym większa, im bardziej skomplikowaną i rozproszoną infrastrukturą zarządzamy.
Jednak wiele z zarejestrowanych w podatności w bazie https://nvd.nist.gov mogą dotyczyć naszej infrastruktury. Dodając do tego podatności wynikające z błędów w konfiguracji może okazać się konieczne wdrożenie całego procesu zarządzania podatnościami wspieranego za pomocą specjalistycznego oprogramowania. Nawet w małych i średnich firmach oraz instytucjach możemy mieć do czynienia z dziesiątkami istotnych zasobów IT – od systemów operacyjnych, aplikacji biznesowych do różnego rodzaju urządzeń mobilnych. W wielu z wykorzystywanych rozwiązaniach informatycznych pojawiają się podatności, które pozostawione mogą stanowić słabość łatwą do wykorzystania przez różnej maści automaty exploitujące i malware. Wykonując skanowanie podatności w niewielkiej infrastrukturze możemy uzyskać wynik dziesiątek lub nawet setek wykrytych podatności. A ich liczba rośnie w każdym roku.
Standard CVSS jest wykorzystywany do klasyfikacji istotności podatności. Każda podatność oznaczana za pomocą identyfikatora w rejestrze CVE (ang. Common Vulnerability and Exposure) jest poddawana klasyfikacji i ocenie, a następnie zapisywana w formie strukturyzowanej i z przypisaną skwantyfikowaną istotnością. Obecnie używana jest wersja CVSS 3.1, jednak w wielu przypadkach bazujemy również na CVSS w wersji 2.0. Ulepszenia wynikające z CVSS 3.1 pozwalają zespołom reagowania na incydenty, bezpieczeństwa IT i cyberbezpieczeństwa na analizę wpływu luk w zabezpieczeniach w celu określenia pilności reakcji.
Administratorzy systemów IT świadomi konieczności zarządzania bezpieczeństwem stosują wytyczne producentów oraz dobre praktyki w celu uzyskania odpowiedniej konfiguracji urządzeń oraz oprogramowania. Jednak ich starania powinny być wspierane przez ciągłe monitorowanie zarówno poprzez skanowanie znanych podatności, jak i sprawdzanie informacji ze źródeł dostępnych na forach i grupach branżowych. Po potwierdzeniu istnienia podatności w naszym środowisku określamy możliwość jej wykorzystania . Uwzględniamy przy tym jak działające urządzenia oraz systemy bezpieczeństwa minimalizują ryzyko wykorzystania wykrytej podatności.
Czy powinniśmy spodziewać się podatności w wykorzystywanym oprogramowaniu? Błędy w oprogramowaniu występują dosyć często. Ich wykrywanie w trakcie procesu produkcji oprogramowania jest czasochłonne i kosztowne. Duża część błędów powodujących luki w mechanizmach bezpieczeństwa jest niestety wykrywana już po wydaniu finalnej wersji oprogramowania.
Staniemy więc przed pytaniem – jak zarządzać taką dużą liczbą podatności? Wykorzystując narzędzia do skanowania oraz pozyskując informacje ze źródeł dostępnych w Internecie. Oczywiście skanowanie za pomocą skanerów to podstawa, jednak nie powinno być jedynym zadaniem w ramach procesu zarządzania podatnościami. Jak pokazuje przykład podatności Log4j, powinniśmy mieć świadomość wykorzystywanych bibliotek open source i posiadać mechanizmy weryfikacji, czy w naszym oprogramowaniu wykorzystującym jedną z nich nie wykryto błędu biblioteki mogącego prowadzić do naruszenia bezpieczeństwa aplikacji.
Obecnie częstym celem złośliwego oprogramowania są aplikacje webowe oraz urządzenia mobilne. Pierwsze zlokalizowane w strefach zdemilitaryzowanych są otwarte na próby zainicjowania sesji przez dowolnego użytkownika Internetu. Pracując na porcie TCP/443 aplikacje tego typu są wystawione na ciągłe skanowanie portów, fingerprinting oraz identyfikację słabych punktów. Podatność Log4j ujawniła powszechność stosowania tej biblioteki i ewentualną skalę możliwego wykorzystania wykrytej słabości za pomocą od ręki dostępnych i bardzo użytecznych exploitów.
[[Wynik wyszukania exploitów Log4j dostępnych pod adresem: https://www.exploit-db.com/]]
![]()
Czy podatność o poziomie wysokim w Log4j była pierwszą w historii tego oprogramowania? Odpowiedź brzmi: nie. Log4j nie jest wyjątkiem. Podobny wniosek dotyczy usługi SMB, która nie jest dostępna (raczej) z zewnętrz, jednak z jest wykorzystywana na ogromną skalę.
[[Podatności o poziomie wysokim w Log4j]]

Wszyscy pamiętamy historię podatności dotyczącej SMBv1 sprzed kilku lat. W usłudze powszechnie używanej przez miliony firm, instytucji i osób prywatnych wykryta została podatność poziomu wysokiego pozwalająca na zdalne przejęcie systemu. Poprawka pojawiła się wiele dni PO publikacji informacji o wykryciu podatności. Niestety efektów podobnych podatności możemy doświadczać z coraz większą częstotliwością.
[[Opis podatności opisanej w biuletynie bezpieczeństwa Microsoft MS17-010-Critical.]]
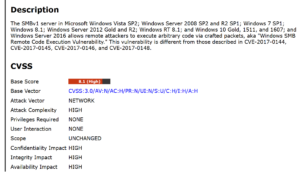
[[Czy możemy czuć się bezpiecznie z wyłączonym SMBv1?

Na każdą podatność bez problemu możemy znaleźć exploita:
# SMBGhost_RCE_PoC
RCE PoC for CVE-2020-0796 „SMBGhost”
Using this for any purpose other than self education is an extremely bad idea. Your computer will burst in flames. Puppies will die. Now that that’s out of the way….
Replace payload in USER_PAYLOAD in exploit.py. Max of 600 bytes. If you want more, modify the kernel shell code yourself.]]
Dostępność exploitów i wymiana wiedzy na ten temat pozwala zarówno adminom, jak i atakującym na zwiększenie efektywności. Niestety obrona zawsze jest o jeden krok za atakującymi.
Autor: Artur Cieślik